
Im SimQuality-Forschungsprojekt haben wir eine Reihe von Regeln für die Prüfung von Simulationsprogrammen entwickelt:
- Prüfergebnisse werden jeweils für eine Kombination aus Programm/Bibliothek, Version, und Prüfer/Ergebnisbereitsteller abgelegt.
- Es werden nur Ergebnisse für veröffentlichte Software erlaubt, d.h. spezifische Programmanpassungen nur zum Zweck der Validierung sind nicht erlaubt. Die geprüften Programme müssen Planern/Ingenieuren auf dem Markt zugänglich sein.
- Die Ergebnisse müssen von Dritten reproduzierbar sein. Dies kann am Einfachsten durch Bereitstellen der Simulationseingangsdaten erreicht werden (dafür gibt es Bonuspunkte bei der Bewertung). Auch eine zusätzliche Dokumentation der Dateneingabe/Modellierung kann helfen das Reproduzieren der Daten zu erleichtern.
Die Angabe der Version erlaubt es, zwischen verschiedenen Entwicklungsstufen einer Software zu unterscheiden.
Die Angabe des Prüfers/Prüfdaten-Bereitstellers erlaubt es, unterschiedliche Kompetenzen/unterschiedliches Detailwissen bei Simulationsanwendern zu berücksichtigen. So hat ein Entwickler der Software sicher ein größeres Detailwissen und kann ggfs. undokumentierte/unbekannte Spezialfunktionen nutzen, die ein „normaler“ Ingenieur vielleicht nicht kennt. Dies hat aber auch den Vorteil, dass die Anwendung dieser Funktionalitäten in der Testreihe erläutert und damit bekannt gemacht werden. Und damit hilft dieses auch allen anderen Anwendern der Software.
Prüfmethodiken
Neben Regressionstests und Modul-/Einheitentests (engl. unit tests) ist das Durchführen von Testreihen und Vergleichen der Simulationsergebnisse gegen Referenzwerte wichtig für die Qualitätssicherung eines Berechnungsprogramms. Leider ist alleine das Formulieren von Testreihen und Prüfkriterien selbst recht schwierig. Das Thema ist in zahlreichen Publikationen aufgegriffen worden und es existieren auch bereits einige Prüfserien und Testreihen.
Es gibt grundlegend verschiedene Prüfmethodiken, um ein Modell auf korrekte Funktionalität zu prüfen. Je nach Verfahren und Autor werden hier verschiedenste Begriffe verwendet, wie Validierung, Verifizierung, Plausibilitätstests, Benchmarking, usw. Eine eindeutige Definition ist unserer Meinung nach nicht wirklich möglich. Wir verwenden allgemein den Begriff Validierung als Synonym für Funktionsprüfung.
Übliche Testverfahren sind:
- Vergleich zwischen Simulationsergebnissen und analytischen Lösungen,
- Vergleich von Simulationsergebnissen mit Messwerten, und
- Vergleich von Simulationsergebnissen mehrere Programme/Modelle untereinander.
Analytische Lösungen
Der Vergleich mit analytischen Lösungen ist bei heutigen Aufgabenstellungen und dynamischen Simulationsprogrammen de-facto nicht möglich. Lediglich für stark vereinfachte Spezialfälle lassen sich analytische Lösungen konstruieren. Diese sind durch die Vereinfachungen jedoch nicht mehr praxisrelevant und Aussagen aus einer analytischen Validierung lassen sich in der Regel nicht verallgemeinern. Eine Ausnahme bilden analytische (Näherungs-)Lösungen für stationäre Wärmebrückenberechnungen.
Vergleich mit Messwerten
Der Vergleich mit Messwerten/Monitoringdaten scheint auf den ersten Blick naheliegend zu sein. Betrachtet man eine Validierung genauer, so ergeben sich jedoch vielfältige Probleme und Fehlerquellen.
In der Regel werden Simulationsprogramme nicht verwendet, das Monitoring bzw. die Messdatenerfassung zu konzipieren. D.h. es wird nicht a-priori geprüft, ob die erfassten Messparameter überhaupt zureichend und geeignet sind, ein Simulationsmodell zu validieren. Stattdessen werden in der Regel zuerst Messwerte erfasst und dann wird versucht, dass Simulationsmodell mit den Daten abzugleichen (oder es werden von Dritten bestimmte Messwerte herangezogen).
Dies bedingt natürlich das Problem, dass bestimmte Freiwerte für Parameter verbleiben, die dann zur Kalibrierung des Modells genutzt werden können. Eine häufige Kritik bei diesem Ansatz ist, dass die Simulationsergebnisse passend „gefittet“ werden. Ein derartiger Abgleich der Simulationsergebnisse mit Messdaten liefert somit lediglich den Nachweis, dass das Simulationsmodell prinzipiell in der Lage ist, die Komplexität der gemessenen Realität (einschließlich potentieller Messfehler) zu reproduzieren.
Bei der Erfassung und Auswertung von Messwerten müssen zahlreiche Fehlerquellen berücksichtigt und minimiert werden:
- Messfehler in Messhardware/Kalibrierung von Sensorik/Sensordrifts etc.,
- Platzierung von Sensoren (bspw. können signifikante Temperaturunterschiede in einem Raumluftvolumen gemessen werden, wenn der Sensor in verschiedenen Positionen platziert wird: abgehängt in Raummitte, an einer Außenwandecke, Innenwandfläche, eher oben oder unten, in Fensternähe/ bzw. der Sonnenstrahlung ausgesetzt, … ; Unterschiede von mehreren Kelvin sind hier möglich)
- Interpretation von Messdaten (Raumlufttemperatur vs. operativer Temperatur; Globalstrahlung oder vorwiegend Diffusstrahlung wegen Eigenverschattung/Fremdverschattung; Oberflächentemperatur oder Temperatur in/über der Grenzschicht; …)
Gerade letzteres ist beim Vergleich von Messdaten mit Simulationsergebnissen kritisch zu betrachten. Simulationsmodelle arbeiten mit Vereinfachungen und Idealisierungen der bebauten Umgebung (bspw. Annahme perfekt durchmischter Raumvolumnia, oder Vernachlässigung von Wärmebrückeneffekten und Annahme homogener Oberflächentemperaturen etc.). Entsprechend müssen Messdaten bzw. Simulationergebnisse dahingehend überprüft werden, ob sie beide die gleiche Aussage treffen. Gerade bei Verwendung von publizierten Messdaten ohne Detailinformationen über Messerfassung, Sensorplatzierung etc. ist das Ergebnis eines Abgleichs mit der Simulation kritisch zu sehen.
Alternativ kann man Sensorik direkt mit dem Ziel der Validierung von Modellen platzieren und dabei bestimmte Störgrößen direkt eliminieren. Aus diesem Grund ist eigentlich immer zu empfehlen, das geplante Monitoring vorab mit dem Simulationsmodell zu prüfen und mit der Simulation eine entsprechende Sensorikauswahl zu treffen und Messmethodik festzulegen.
Vergleich verschiedener Modelle und Implementierungen
Eine weitere Form der Validierung ist der Vergleich verschiedener Simulationsmodelle untereinander. Wenn die zu vergleichenden Modelle einen ähnlichen Aufgabebereich abdecken und ähnliche Genauigkeitsanforderungen erfüllen sollen, darf man eine hinreichend große Übereinstimmung der Modellergebnisse erwarten. Dies bedingt jedoch einige Voraussetzungen:
- die Modelle müssen hinsichtlich Modellkomplexität und abgebildeter Effekte vergleichbar sein,
- die Modelle müssen gleich oder zumindest ähnliche Parameter verwenden; oder es muss klar definiert und eindeutige Umrechnungsvorschriften zwischen Modellparametern geben,
- die Ergebnisgrößen müssen vergleichbar sein (bereits der Vergleich von Stundenmittelwerten der Temperatur und Momentanwerten der Temperatur kann je nach Anwendungsfall zu größeren Abweichungen führen),
- die numerischen Algorithmen müssen der mathematischen Formulierung angemessen sein; zu starke Gleichungsvereinfachungen zum Zweck der Implementierung dürfen nicht zu Approximationsfehlern führen (bspw. Verwendung stationärer Gleichungen für stark dynamische Prozesse; zu große Mittelungsintervalle etc.); auch müssen vergleichbare Numerikparameter verwendet werden, wenn diese einen Einfluss auf die Ergebnisse haben (bspw. Gitterdetailstufen bei FEM/FVM Methoden etc.)
- die Softwareimplementierungen dürfen keine Fehler enthalten
In der Realität ist es schwierig, alle diese Bedingungen einzuhalten. Entsprechend ergeben sich beim modellseitigen Vergleich zwischen verschiedenen Programmen für ein gewähltes realistisches Anwendungsszenario zum Teil sehr viele Ergebnisvarianten, wie nachfolgend dargestellt:
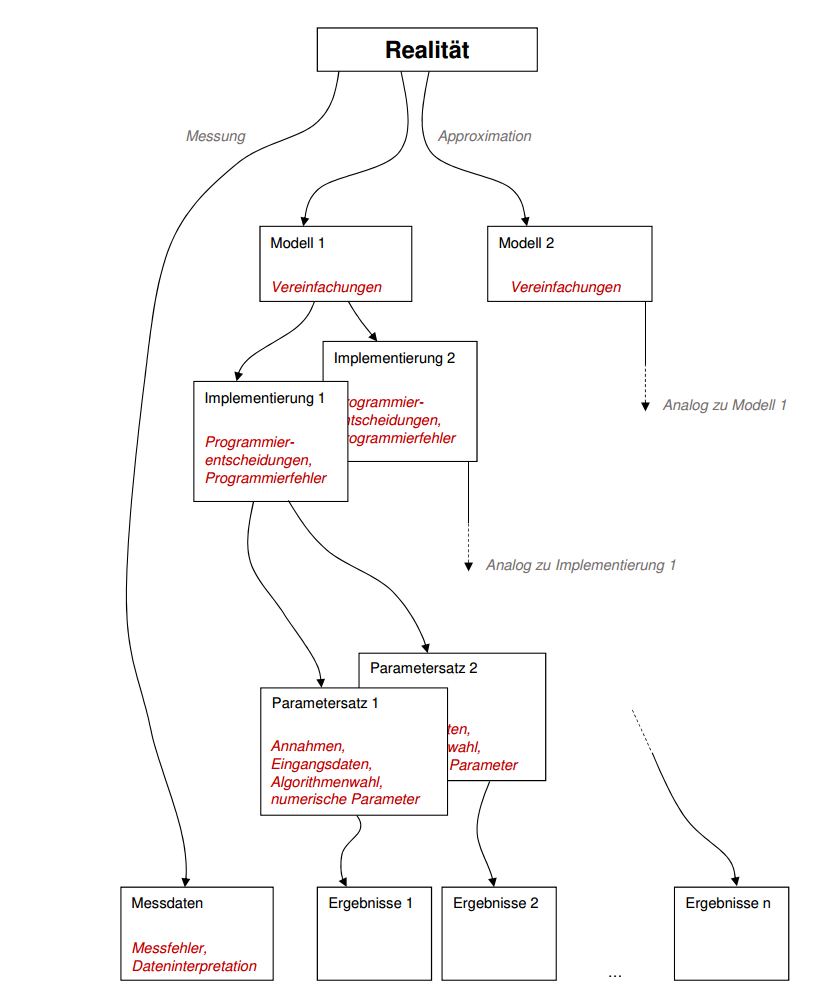
Homogenisierung von Modell-Modell-Vergleichen
Es gibt verschiedene Möglichkeiten, die Variationsbreite beim Modell-Modell-Vergleich zu reduzieren. Ausgehend von der Forderung nach gleichwertiger Anwendbarkeit der Modelle können verschiedenen Szenarien definiert werden, in denen Modellkomponenten spezifisch geprüft werden. Komplextests, bei denen viele Modellkomponenten gleichzeitig aktiv sind, bergen immer das Risiko, dass Fehlerquellen in einzelnen Modellkomponenten durch andere physikalische Effekte verwaschen werden, oder dass sich unterschiedliche Fehler kompensieren. Daher ist es zielführender, individuelle Komponententests durchzuführen, in denen jeweils bestimmte Modellfunktionalitäten mit einer Bandbreite an Parameter geprüft und verglichen werden. Dabei werden die zu verwendenden Parameter sehr genau vorgegeben, und auch das zu verwendende physikalische Modell entsprechend der Ergebnisanforderung detailliert beschrieben.
Bei Verwendung derartiger Komponententests lassen sich Programmierfehler oder Modellgenauigkeitsprobleme direkt identifizieren. Korrekte Modellergebnisse liegen bei diesen individuellen Tests häufig in einem sehr engen Korridor, welches die Definition von Validierungskriterien erleichtert.
Dieser Ansatz der Modell-Modell-Validierung durch individuelle Komponententests wird durch SimQuality in der SimQuality (2020) Testsuite verfolgt.